fresco介绍
说到android图片加载框架,我们都熟悉glide,Picasso.fresco等,由于我们公司使用了react-native作为了主要的跨平台开发框架,其中自然而然的集成了facebook的fresco。所以,在这里主要分析一下fresco是怎么加载图片的.
在使用方面fresco是其中最复杂的,但是它的优势也是比较明显的,主要是在以下这几个方面:
图片的渐进式呈现。
支持动图加载:加载Gif、WebP动图,每一帧都是一张很大的Bitmap,每个动画都有很多帧。Fresco能管理好每一帧并管理好你的内存。
丰富的图片处理:缩放、圆角、透明、高斯模糊等处理。
在5.0以下系统,Bitmap缓存位于`ashmem,这样Bitmap对象的创建和释放将不会引发GC,更少的GC会使你的App运行得更加流畅。
良好的代码设计,代码可扩展性非常好。
fresco加载图片流程
我们知道图片加载框架,为了加快下次图片的加载速度,一般是有其缓存机制的,而fresco的缓存机制也和大多数图片加载库一样,有着memory cahce&disk cache,但是fresco缓存策略比较复杂,分为:bitmap缓存,未解码图片的内存缓存,磁盘缓存。fresco有着三级缓存。
注解:所谓图片是否解码,指的是图片是以bitmap的形式存在,还是二进制流的形式存在。未解码表示是二进制流的形式,解码表示将二进制流转为bitmap对象。
简易的加载流程如下,
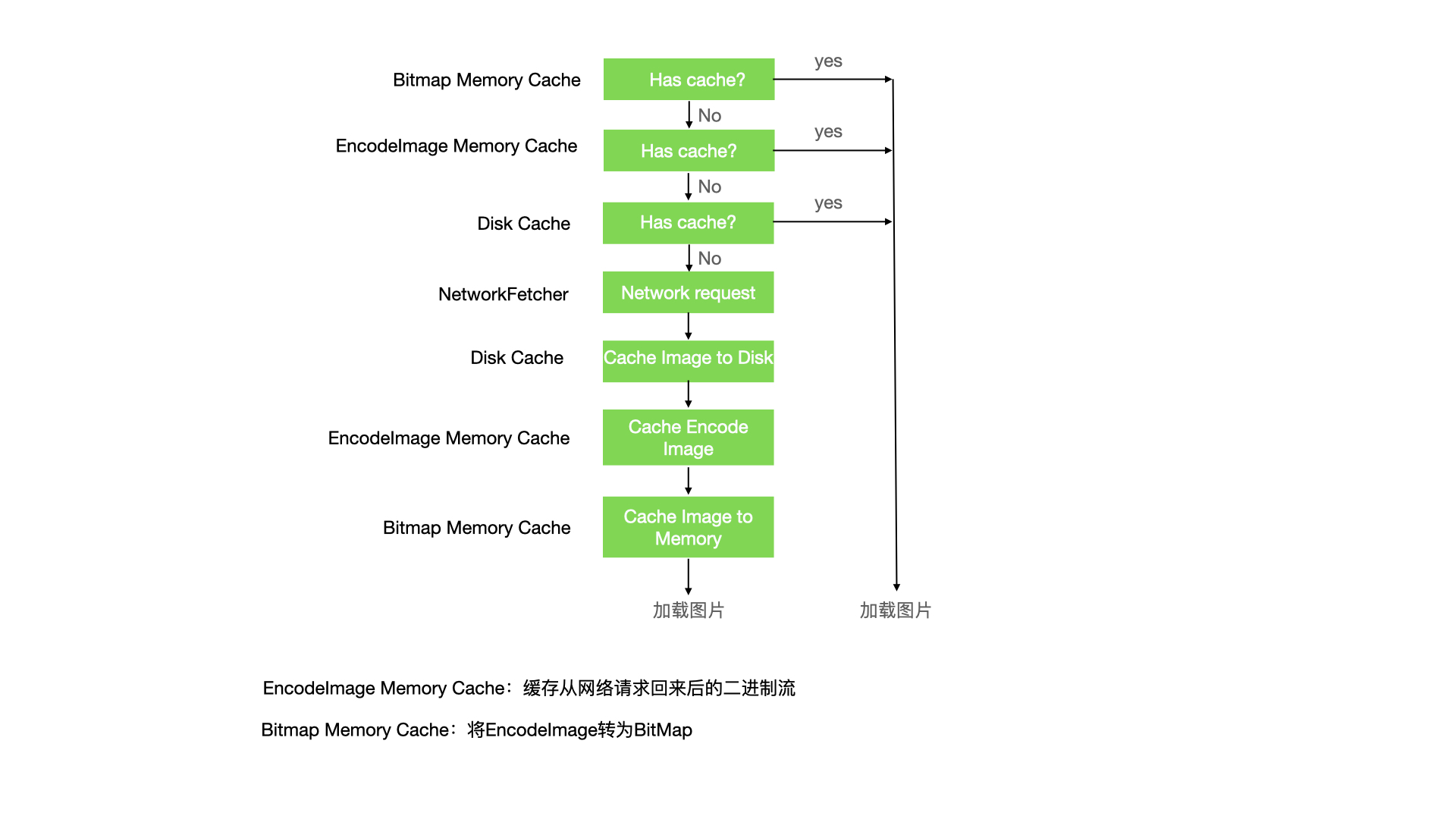
因为在具体的图片加载逻辑中,设计到各种缓存,decode,裁剪图片等操作,流程是非常复杂的,下面是正常图片加载Producer和Consumer的流程。
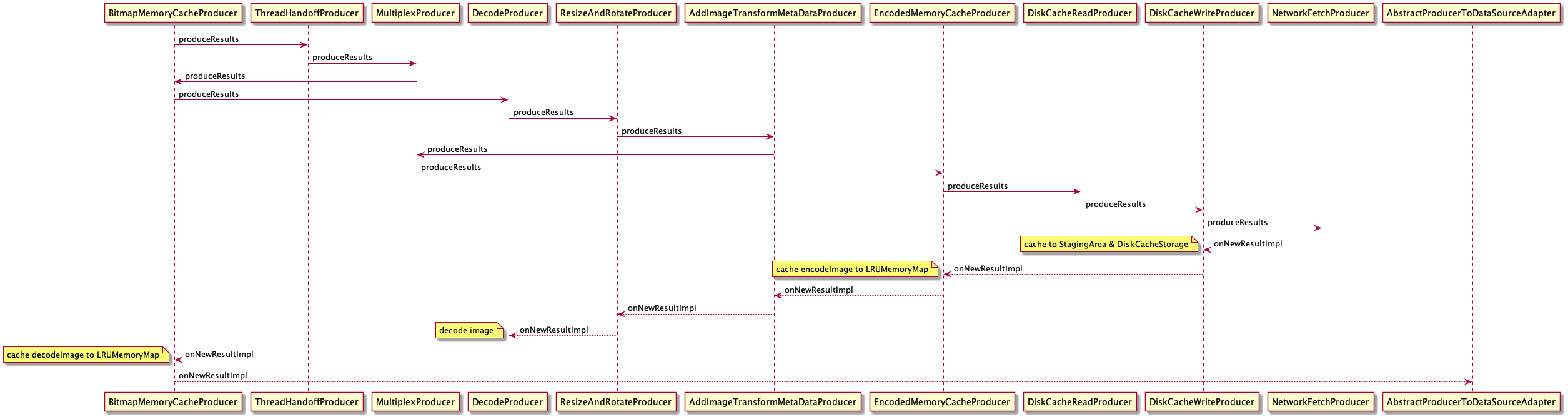
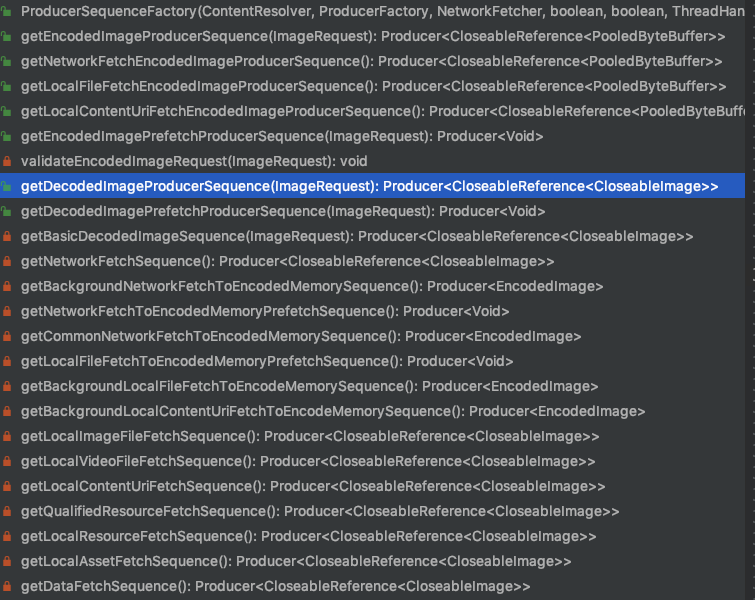
关于这块的逻辑,fresco设计的非常巧妙,使用装饰器和责任链模式混用的方式,使得代码结构变得非常容易扩展,而且想要自己定义图片的加载顺序,只需要按照相应的顺序,嵌套new一个producer sequence就可以了。我们目前请求图片就是用的getDecodedImageProducerSequence这个sequence.
1 | public DataSource<CloseableReference<CloseableImage>> fetchDecodedImage( |
fresco有个producerSequenceFactory有许多不同的producer sequence,方便我们根据不同的场景选择不同的sequence。
关于producer和consumer的设计,我使用ts写了一个简单的实现,可以一块预览一下。
bitmapMemoryCache && encode Image Cache
bitmapMemoryCache和EncodedMemoryCache是使用的相同的数据结构,MemoryCache来存储的。主要区别是bitmapMemoryCache缓存的是CloseableImage,而EncodedMemoryCache缓存的是PooledByteBuffer字节流。
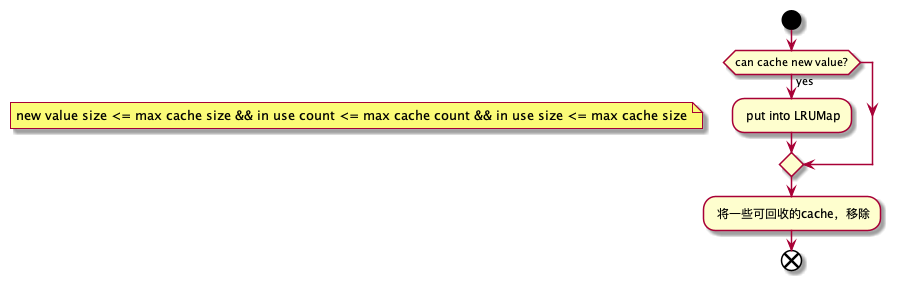
LRUMap: Least Recently Used Map,即最近最少使用,是一种常用的页面置换算法,选择最近最久未使用的页面予以淘汰。 也常见于软件开发中,用于处理一些缓存策略。
fresco中使用LinkedHashMap实现LRU算法,LinkedHashMap是jdk中,一个具有双链表的Map,是一个有序的HashMap,这里的有序指的是元素的插入顺序。
disk cache
fresco磁盘缓存是分为SMALL,DEFAULT两种,这两种策略的都是用BufferedDiskCache做的缓存,因此,直接分析这个类就可以了。
1 | public void put(final CacheKey key, EncodedImage encodedImage) { |
首先是按照[cacheKey,EncodeImage]的方式,将其缓存在Map中,接下来会开启一个线程,用来异步存储encodeImage到disk中。在这里通过图片的url,经过SHA1加密和base64转码,之后得到一个resourceId,主要用来生成存储文件的文件名,文件名格式为:/data/user/0/package/cache/image_cache/v2.ols100.1/95/mtQL41H7RDPU2uZo1zMCo5fto-Q.4178151137210219191.tmp
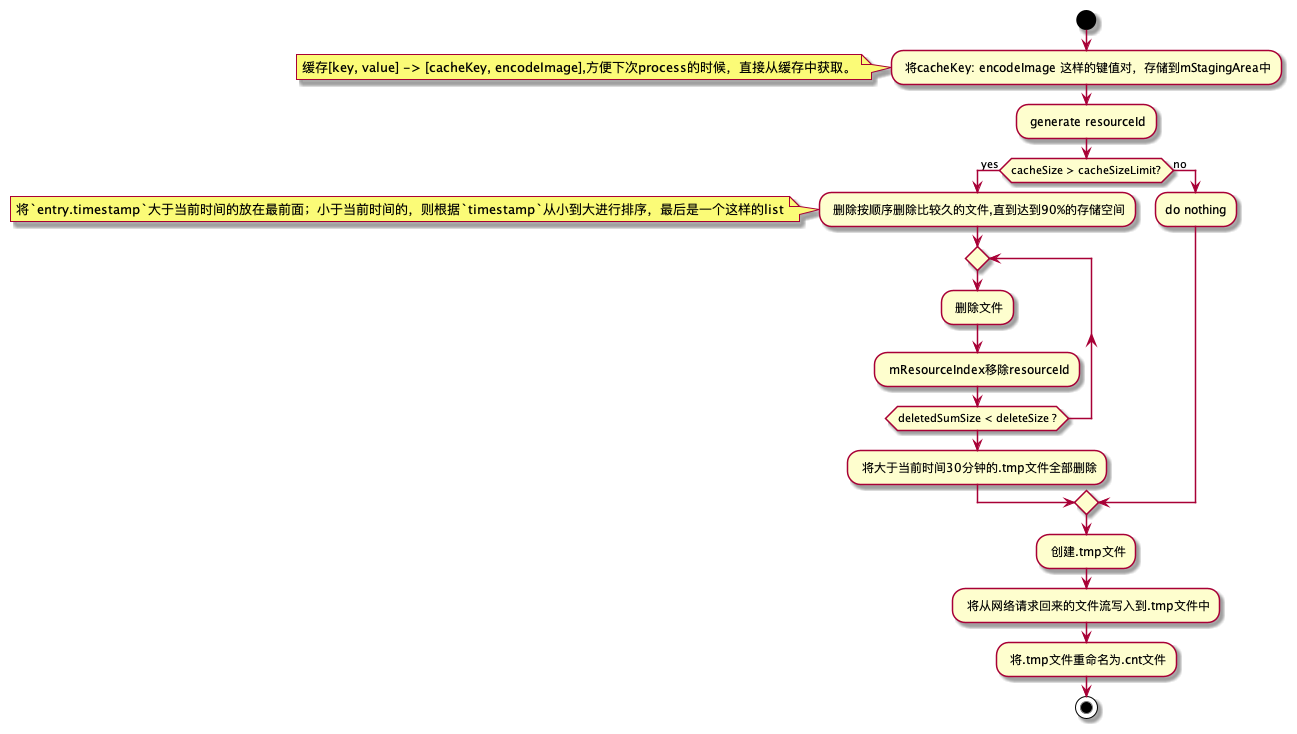
图片加载网络请求
fresco关于图片的网络请求,抽象出来一个NetworkFetcher接口来处理,因此,开发者可以通过继承NetworkFetcher,使用自己熟悉的网络请求库来封装。fresco内部已经有了volley,okhttp,httpUrlConnection三种网络库的实现。

ReactImageView是如何加载的?
1.1qrn是如何加载的?
首先我们先分析一下qrn是如何加载的?我们打开一个rn页面,一般是通过scheme的形式打开,scheme的类似:qunariphone://react/open?hybridId=f_home_rn&pageName=Home&initProps=${encodeURIComponent ( JSON.stringify ({"param":{"cityName":"xx”,"bd_source":"xx”}}))},经过native代码桥接的QRCTJumpHandleManagermodule配合动态路由,跳转到QReactNativeActivity页面,再调用QReactHelper#doCreate开始,创建rn环境。
qrn对于ReactInstanceManager的缓存处理
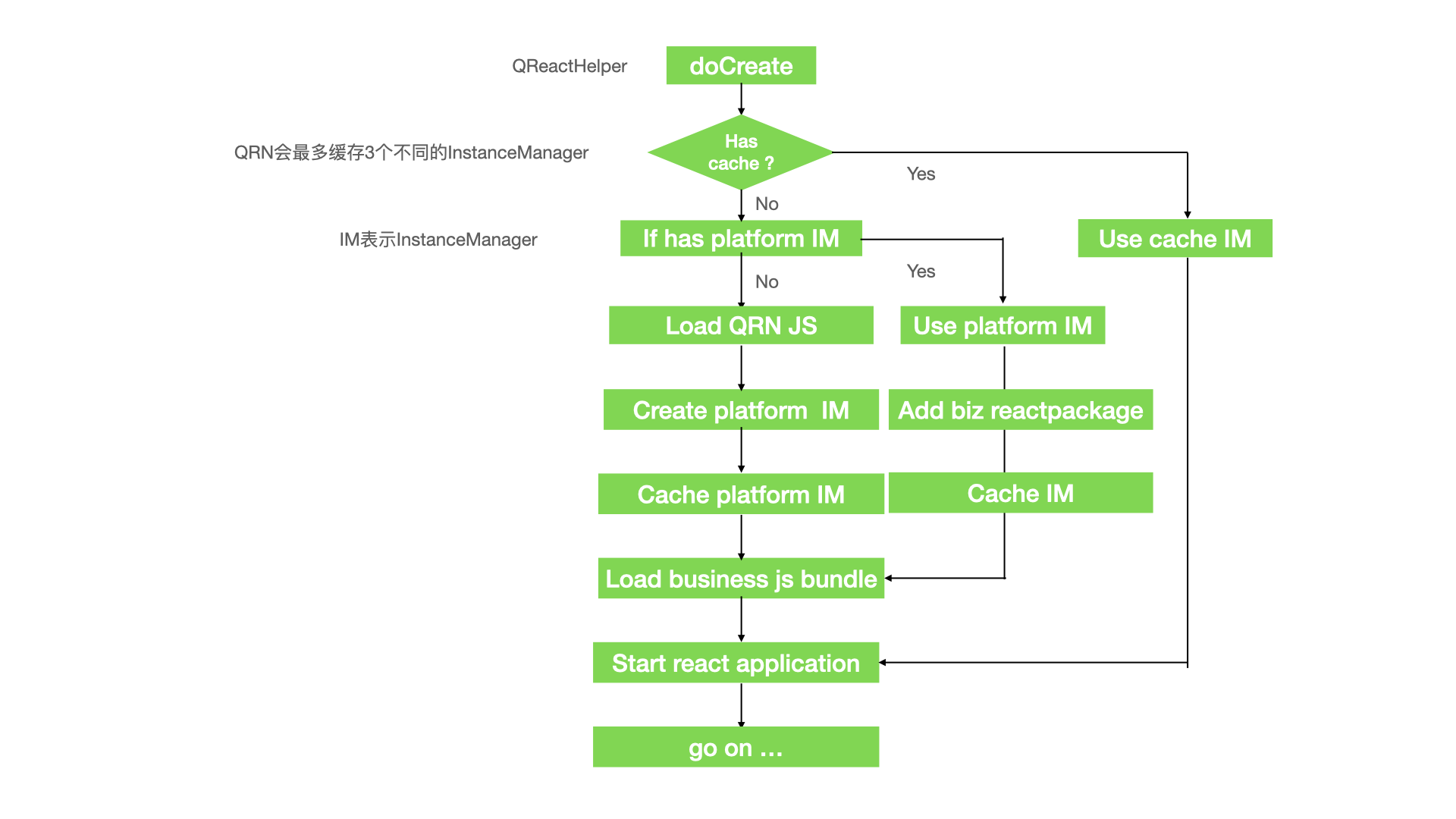
创建rn环境:
1.2 Image标签的渲染
以上react-native环境是初始化完成,接下来分析一下,用react编写的Image是如何渲染到页面上的。
一个简单的列子,
1 | import React, { Component } from 'react'; |
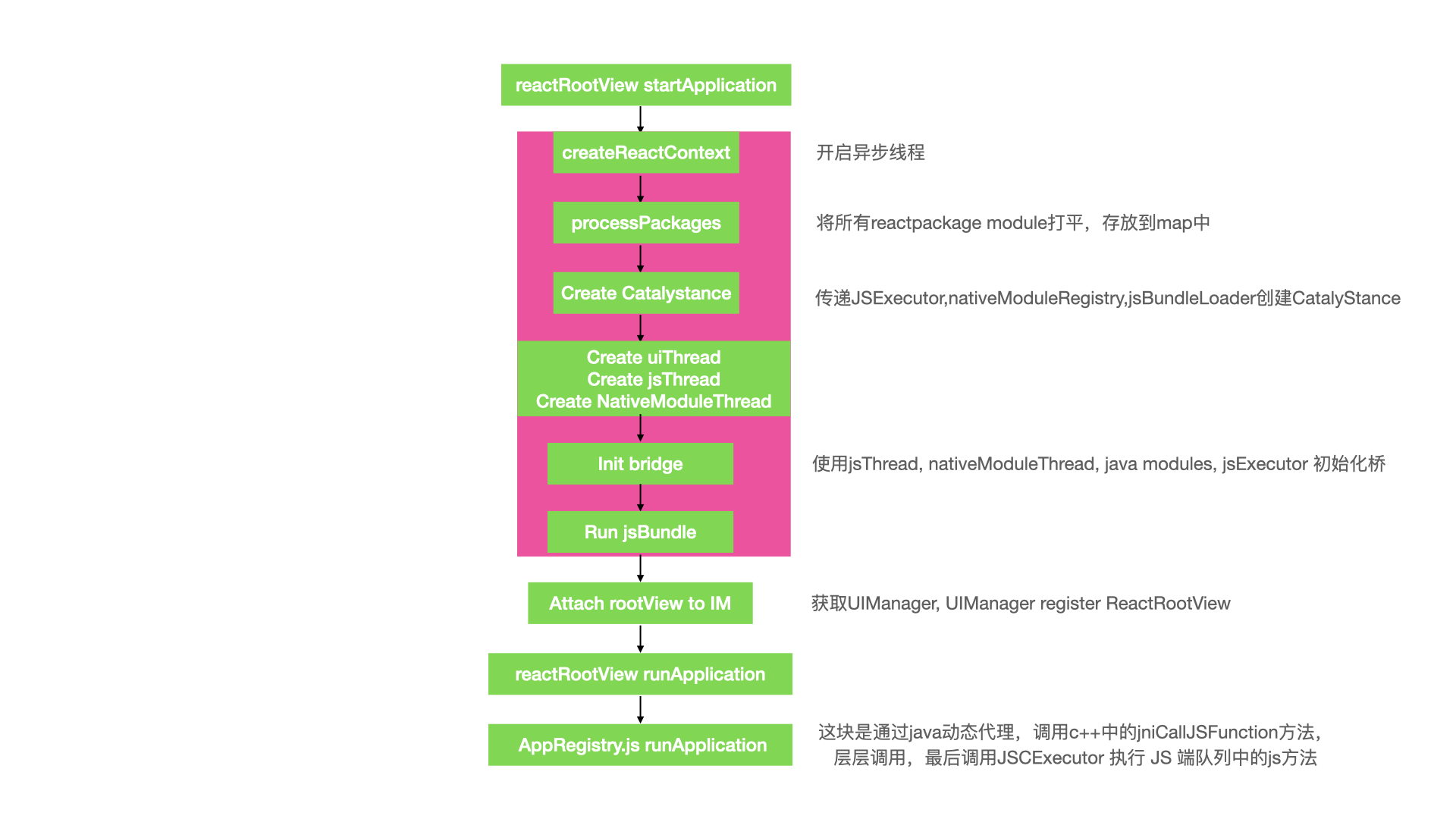
AppResgistry注册完组件之后,Native端调用AppRegistry的runApplication开始渲染组件。
写过原生android的同学都知道,android一般用布局方式是LinearLayout,RealativeLayout,FrameLayout等,并没有所谓的flex布局,facebook使用c++实现了一套flex布局,即Yoga.
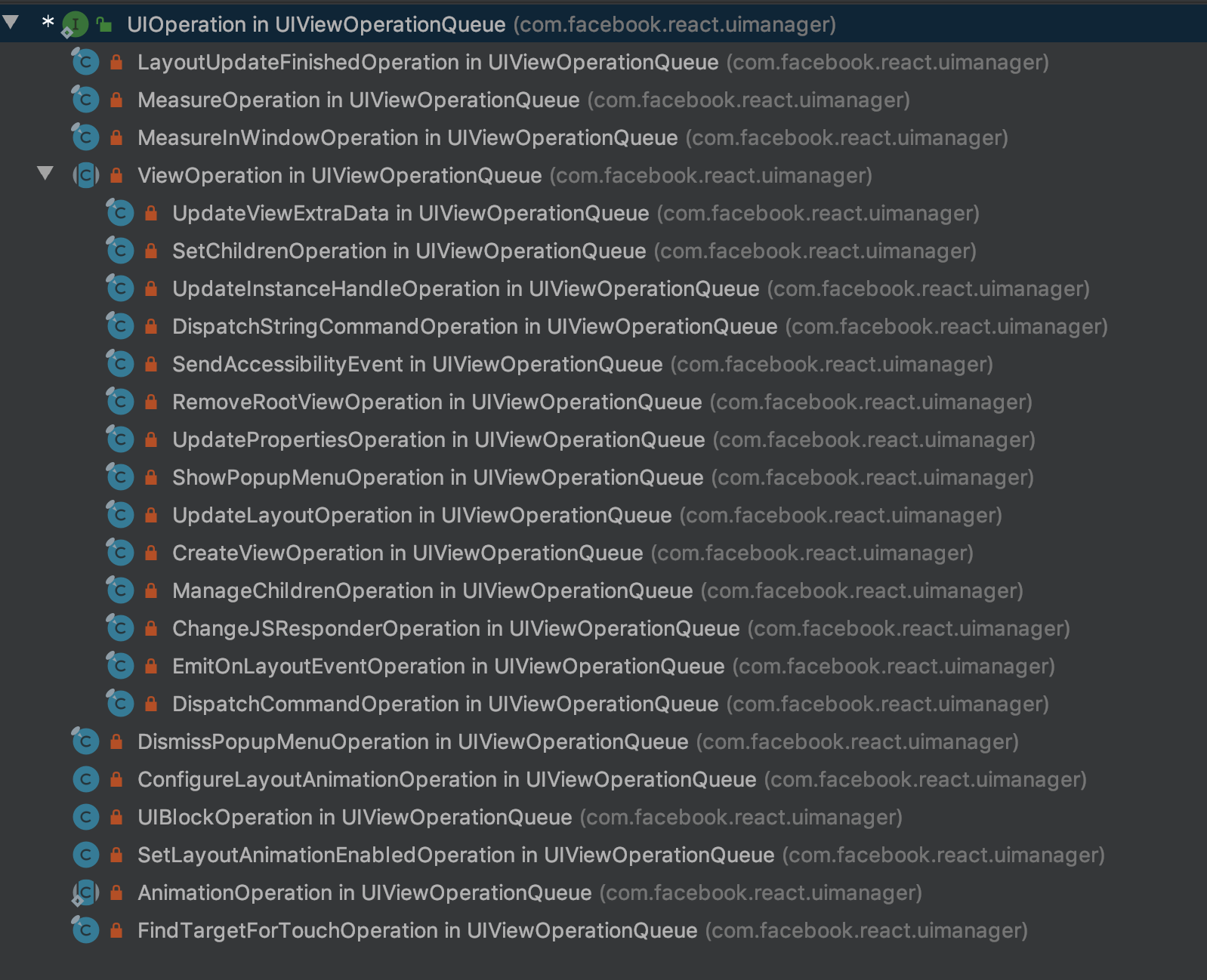
在js端,facebook实现了一套虚拟的dom树结构,可以在ReactNativeRender-prod.js查看其实现方式,在ReactNativeRender中,react-native将所有的view操作都抽象为了UI操作,对应的是native side 的UIOpeation,比如:创建view,更新view,测量view。对应的是CreateViewOperation,UpdateViewExtraData,MeasureOperation.
大致流程如下图所示:
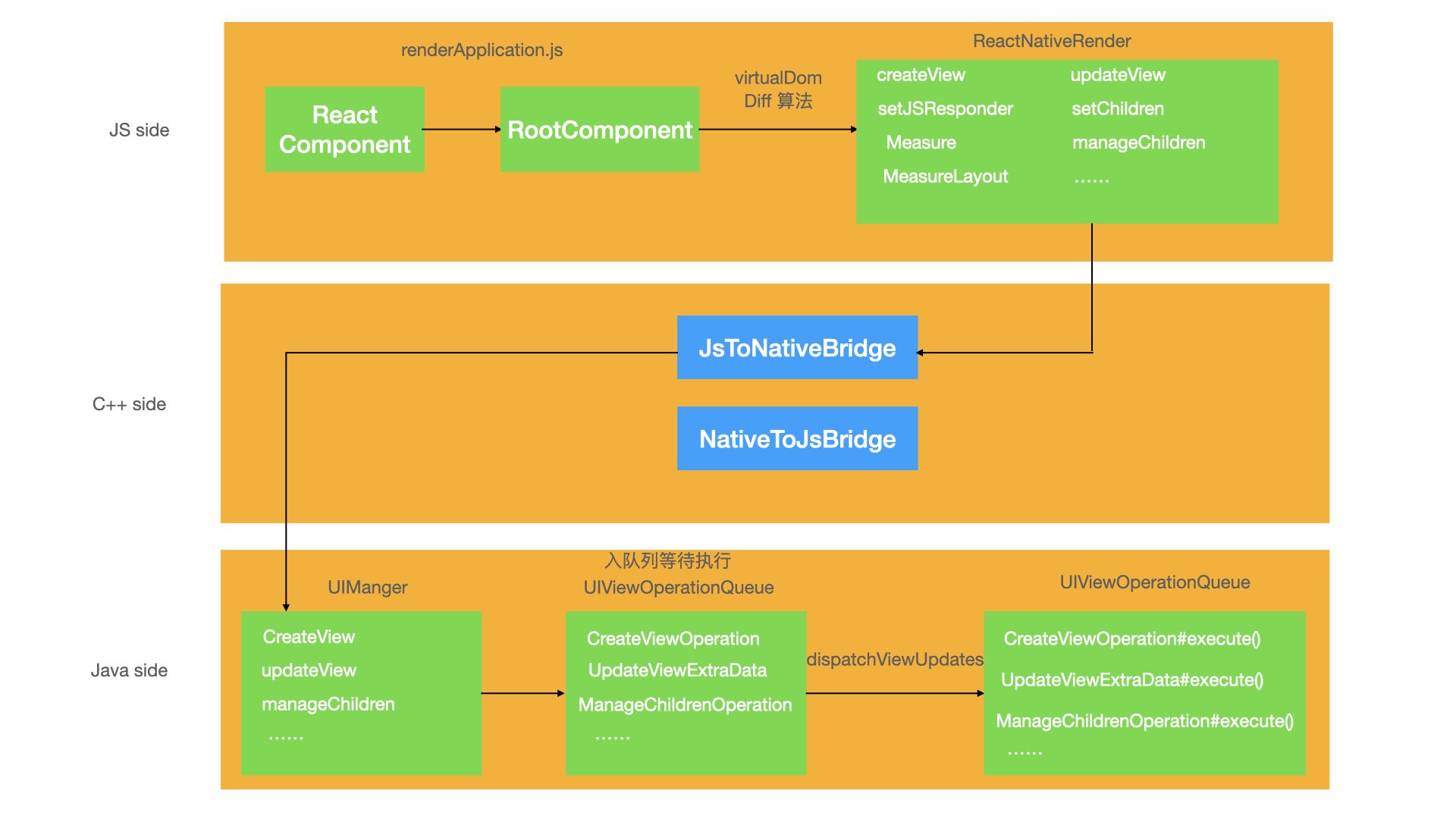
React Component在native端View的映射:

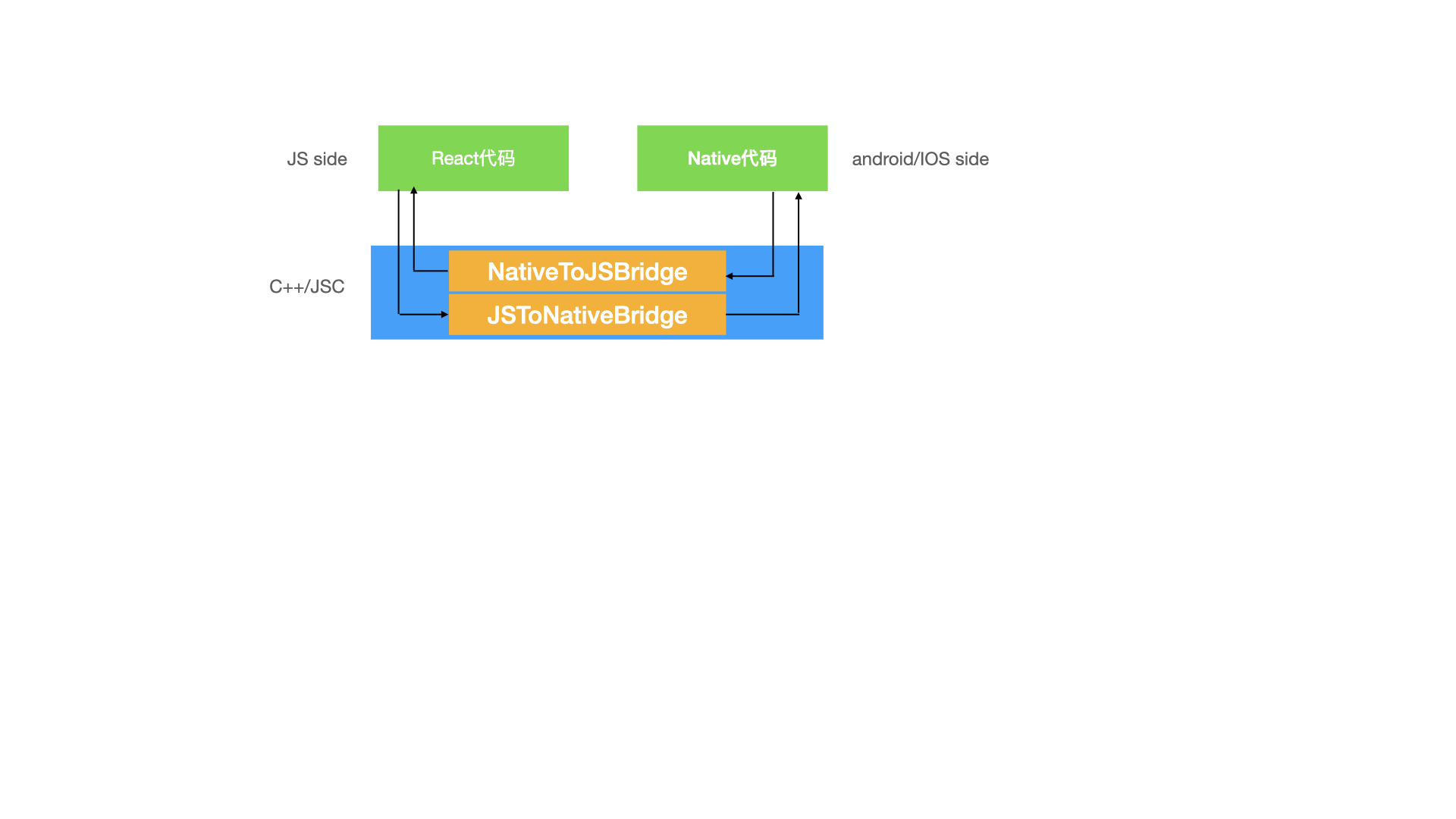
native和js端双边通信简易图:
参考文档
https://juejin.cn/post/6844903559280984071
https://yanbober.blog.csdn.net/article/details/53157456



